Reading Time: 4 minutes
Number of Words: 854

Maximum Website Size analyzed by Googlebot on a web page
A web page is an HTML document that contains information and content on various topics. Depending on the information and content included on a web page, the length of a webpage varies. Generally, the larger a webpage is, the more content it has and the more links it has. A webpage's size can be expressed in bytes- equal to 1,000 bytes equal to 1 megabyte. A web page containing rich information and multimedia will be larger than one with less content. A HTML document is typically uploaded to a webserver where it is accessible to the general public via a web browser.
In October 2014, Google announced that it would no longer cache webpages larger than 4 megabytes for its users. This limit applies to all web browsers operating on all platforms. In addition, Google announced that from February 10th 2016 onwards, it will stop rendering pages larger than 3 megabytes in web browsers and search engines alike. To understand how large webpages should be for Googlebot to consider them relevant, let us look at some technical information about how this bot crawls the internet.
Recently, Google has announced that it will not crawl HTML code of web pages larger than 15 MG. This is really ridiculous, since most web pages have an average size of 30 KB. If your web page is that big, you are really doing something wrong.
As for the size of content such as photos or videos uploaded from a web page, that is not taken into account by Googlebot, since from an html page, this type of content is simply linked, so google does not interpret this as remarkable size to add within the html content.
An easy way to see the size of each web page is to use lookkle.com's file size analyzer.
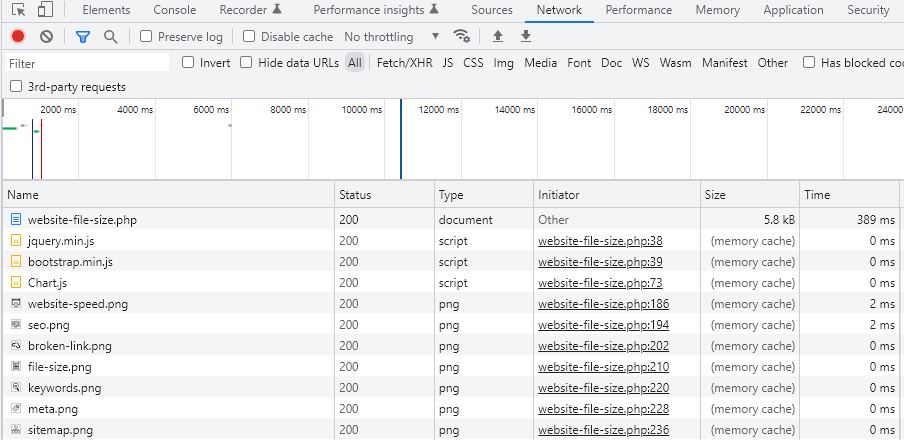
Another easy method is from the inspector of our web browser, easily accessible by pressing the F12 key on our keyboard. With the browser's inspector window open, simply scroll to the Network tab and analyze the size and status of each of the files on your web site, and you will see that overall it is really ridiculous. To make a more complete analysis it is better to refresh the page once the browser inspector is open.
Google maintains an array of artificial intelligence algorithms that constantly analyze data from various sources on the internet. For example, when Googlebot encounters a webpage, it processes it using various parameters such as text and image analysis, link analysis and hyperlink auditing. After processing a webpage, Googlebot generates a list of potential links for each page. It also generates a list of potential images for each webpage and assesses the text. Based on its analysis, it identifies whether a webpage is relevant or not and whether to keep or discard it.
To understand how Google decides whether a web page is relevant or not, we must understand what makes a page relevant or not. Google considers relevant webpages those that answer user queries or provide information that is useful to the user- this is called user relevance. Other factors that affect relevance are website quality and freshness- websites with newer content are more likely to be considered relevant than websites with old content- this is called website quality. Freshness refers to the timeliness of a webpage; if the data on a webpage is outdated, this factor may cancel out its relevance instead of amplifying it.
To determine how large Googlebot should consider a webpage when judging its relevancy, we need to look at how google crawls websites and identifies pages as relevant or not. When encountering a webpage- especially one with many links- GoogleBot initially processes it by identifying images and text. After processing a webpage, Googlebot generates a list of potential links for each page. It also generates a list of potential images for each webpage and assesses the text in an automated fashion through optical character recognition (OCR). Based on its analysis, it identifies whether a webpage is relevant or not and whether to keep or discard it. All these steps consume resources on Google's server so that its users can easily access relevant information on the internet via their web browsers and other devices connected to the internet.
From our discussion thus far, we can draw certain conclusions regarding what limits Google sets for how large its crawler can consider any website when identifying potential links or pages relevant to its users' queries. First, as part of its effort to accelerate user experience, Google sets limits on how large websites that users commonly access can be- anywhere from 1 MB up to 4 MB in October 2014 and 3MB thereafter for all web browsers and search engines alike. Furthermore, Google sets limits on how long these websites can remain cached in order to preserve server resources for rendering more relevant information for users' queries. Ultimately determining what limits these are requires knowing how complex website analysis tasks are for an AI bot like Googlebot working 24/7 365 days per year without annual summer breaks!
Tips on SEO and Online Business
Next Articles








Previous Articles